
Pode parecer loucura, mas o sedcomando do Linux é um editor de texto sem interface. Você pode usá-lo na linha de comando para manipular texto em arquivos e fluxos. Mostraremos como aproveitar seu poder.
Índice
O poder do sed
O sedcomando é um pouco como o xadrez: leva uma hora para aprender o básico e uma vida inteira para dominá-lo (ou, pelo menos, muita prática). Mostraremos uma seleção de estratégias iniciais em cada uma das principais categorias de sedfuncionalidade.
sedé um editor de fluxo que funciona com entrada canalizada ou arquivos de texto. No entanto, ele não possui uma interface de editor de texto interativo. Em vez disso, você fornece instruções para que ele siga à medida que avança no texto. Tudo isso funciona no Bash e em outros shells de linha de comando.
Com sedvocê pode fazer o seguinte:
- Selecionar texto
- Texto substituto
- Adicionar linhas ao texto
- Excluir linhas do texto
- Modificar (ou preservar) um arquivo original
Estruturamos nossos exemplos para apresentar e demonstrar conceitos, não para produzir os comandos mais concisos (e menos acessíveis) sed. No entanto, as funcionalidades de correspondência de padrões e seleção de texto sed dependem fortemente de expressões regulares ( regexes ). Você precisará de alguma familiaridade com eles para obter o melhor deles sed.
Um Exemplo Simples
Primeiro, vamos usar echopara enviar algum texto para sed através de um tubo e sed substituir uma parte do texto. Para fazer isso, digitamos o seguinte:
echo howtogonk | sed 's / gonk / geek /'
O echocomando envia “howtogonk” para sed, e nossa regra de substituição simples (o “s” significa substituição) é aplicada. sed pesquisa o texto de entrada em busca de uma ocorrência da primeira string e substituirá todas as correspondências pela segunda.
A string “gonk” é substituída por “geek” e a nova string é impressa na janela do terminal.

As substituições são provavelmente o uso mais comum de sed. Antes de nos aprofundarmos nas substituições, entretanto, precisamos saber como selecionar e combinar o texto.
Selecionando Texto
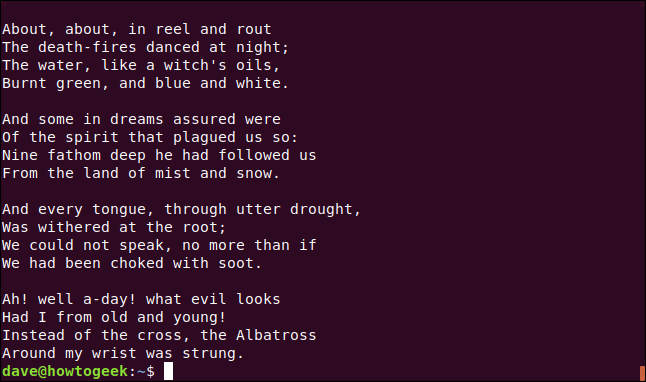
Vamos precisar de um arquivo de texto para nossos exemplos. Usaremos um que contém uma seleção de versos do poema épico de Samuel Taylor Coleridge “The Rime of the Ancient Mariner”.
Nós digitamos o seguinte para dar uma olhada com less:
menos coleridge.txt
Para selecionar algumas linhas do arquivo, fornecemos as linhas de início e fim do intervalo que queremos selecionar. Um único número seleciona essa linha.
Para extrair as linhas de um a quatro, digitamos este comando:
sed -n '1,4p' coleridge.txt
Observe a vírgula entre 1e 4. Os pmeios “imprimir linhas correspondentes.” Por padrão, sed imprime todas as linhas. Veríamos todo o texto no arquivo com as linhas correspondentes impressas duas vezes. Para evitar isso, usaremos a -nopção (silencioso) para suprimir o texto sem correspondência.
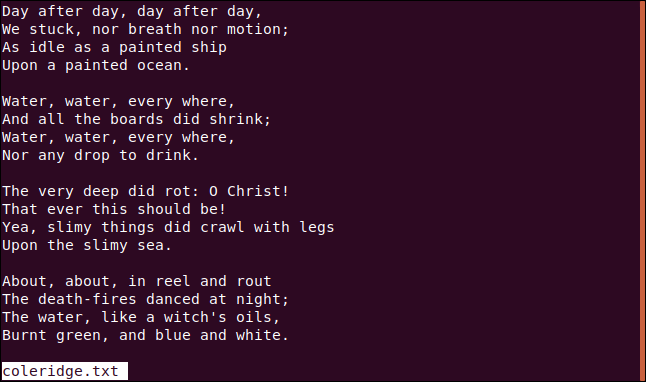
Mudamos os números das linhas para que possamos selecionar um versículo diferente, conforme mostrado abaixo:
sed -n '6,9p' coleridge.txt
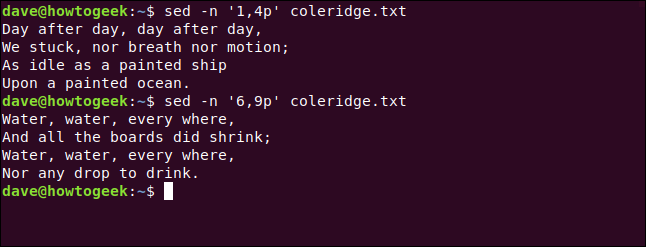
Podemos usar a -eopção (expressão) para fazer várias seleções. Com duas expressões, podemos selecionar dois versos, assim:
sed -n -e '1,4p' -e '31, 34p 'coleridge.txt
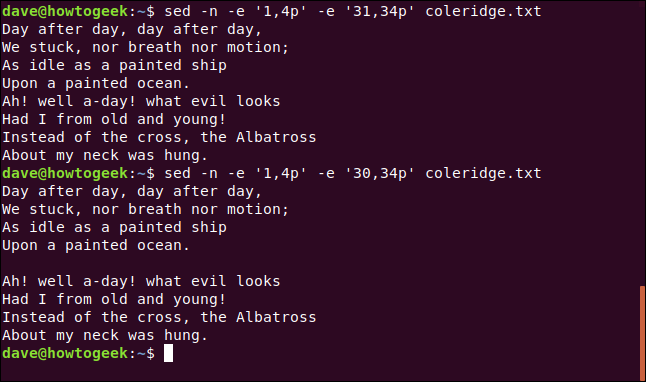
Se reduzirmos o primeiro número na segunda expressão, podemos inserir um espaço em branco entre os dois versos. Nós digitamos o seguinte:
sed -n -e '1,4p' -e '30, 34p 'coleridge.txt
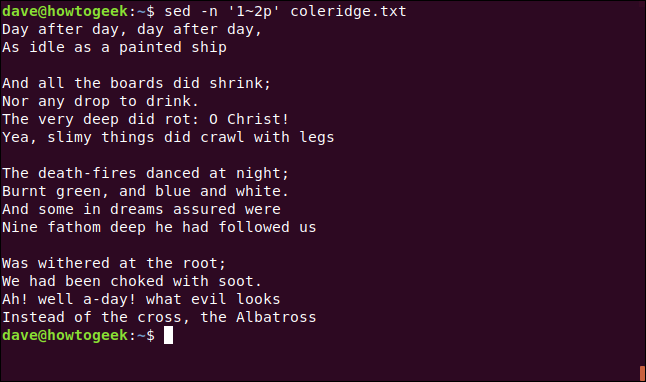
Também podemos escolher uma linha de partida e dizer sed para percorrer o arquivo e imprimir linhas alternativas, a cada cinco linhas, ou pular qualquer número de linhas. O comando é semelhante aos que usamos acima para selecionar um intervalo. Desta vez, no entanto, usaremos um til ( ~) em vez de uma vírgula para separar os números.
O primeiro número indica a linha de partida. O segundo número informa sedquais linhas após a linha de partida queremos ver. O número 2 significa cada segunda linha, 3 significa cada terceira linha e assim por diante.
Nós digitamos o seguinte:
sed -n '1 ~ 2p' coleridge.txt
Você nem sempre saberá onde o texto que está procurando está localizado no arquivo, o que significa que os números das linhas nem sempre ajudam muito. No entanto, você também pode usar sed para selecionar linhas que contenham padrões de texto correspondentes. Por exemplo, vamos extrair todas as linhas que começam com “E”.
O acento circunflexo ( ^) representa o início da linha. Colocaremos nosso termo de pesquisa entre barras ( /). Também incluímos um espaço após “E” para que palavras como “Android” não sejam incluídas no resultado.
Ler sedscripts pode ser um pouco difícil no início. O /p “print”, meios tal como aconteceu nos comandos que usamos acima. No comando a seguir, porém, uma barra o precede:
sed -n '/ ^ E / p' coleridge.txt
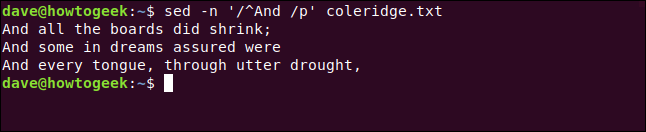
Três linhas que começam com “E” são extraídas do arquivo e exibidas para nós.
Fazendo substituições
Em nosso primeiro exemplo, mostramos o seguinte formato básico para uma sedsubstituição:
echo howtogonk | sed 's / gonk / geek /'
O sdiz que sed isso é uma substituição. A primeira string é o padrão de pesquisa e a segunda é o texto com o qual queremos substituir o texto correspondente. Claro, como em todas as coisas do Linux, o diabo está nos detalhes.
Nós digitamos o seguinte para alterar todas as ocorrências de “dia” para “semana” e dar ao marinheiro e ao albatroz mais tempo para se relacionarem:
sed -n 's / dia / semana / p' coleridge.txt
Na primeira linha, apenas a segunda ocorrência de “dia” é alterada. Isso ocorre porque sedpara após a primeira correspondência por linha. Temos que adicionar um “g” no final da expressão, conforme mostrado abaixo, para realizar uma pesquisa global para que todas as correspondências em cada linha sejam processadas:
sed -n 's / dia / semana / gp' coleridge.txt
Isso corresponde a três dos quatro na primeira linha. Como a primeira palavra é “Dia” e seddiferencia maiúsculas de minúsculas, ela não considera essa instância igual a “dia”.
Digitamos o seguinte, adicionando um i ao comando no final da expressão para indicar que não diferencia maiúsculas de minúsculas:
sed -n 's / dia / semana / gip' coleridge.txt
Isso funciona, mas você nem sempre deseja ativar a não diferenciação de maiúsculas e minúsculas para tudo. Nesses casos, você pode usar um grupo regex para adicionar insensibilidade a casos específicos de padrão.
Por exemplo, se colocarmos os caracteres entre colchetes ( []), eles serão interpretados como “qualquer caractere desta lista de caracteres”.
Digitamos o seguinte e incluímos “D” e “d” no grupo, para garantir que corresponda a “Dia” e “dia”:
sed -n 's / [Dd] ay / semana / gp' coleridge.txt
![O "sed -n 's / dia / semana / p' coleridge.txt," "sed -n 's / dia / semana / gp' coleridge.txt," "sed -n 's / dia / semana / gip' coleridge.txt, "e" sed -n 's / [Dd] ay / week / gp' coleridge.txt "comandos em uma janela de terminal.](https://maisgeek.com/wp-content/uploads/2020/10/x16.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.IZvoVbRvNb.png)
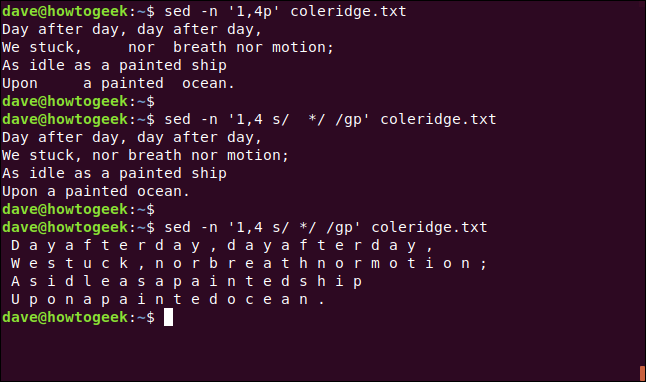
Também podemos restringir as substituições a seções do arquivo. Digamos que nosso arquivo contenha espaçamentos estranhos no primeiro verso. Podemos usar o seguinte comando familiar para ver o primeiro versículo:
sed -n '1,4p' coleridge.txt
Vamos procurar dois espaços e substituí-los por um. Faremos isso globalmente para que a ação se repita em toda a linha. Para ser claro, o padrão de pesquisa é espaço, espaço asterisco ( *) e a string de substituição é um único espaço. O 1,4restringe a substituição às primeiras quatro linhas do arquivo.
Reunimos tudo isso no seguinte comando:
sed -n '1,4 s / * / / gp' coleridge.txt
Isso funciona muito bem! O padrão de pesquisa é o que é importante aqui. O asterisco ( *) representa zero ou mais do caractere anterior, que é um espaço. Assim, o padrão de pesquisa está procurando strings de um ou mais espaços.
Se substituirmos um único espaço por qualquer sequência de vários espaços, retornaremos o arquivo ao espaçamento regular, com um único espaço entre cada palavra. Isso também substituirá um único espaço por um único espaço em alguns casos, mas não afetará nada adversamente – ainda obteremos o resultado desejado.
Se digitarmos o seguinte e reduzirmos o padrão de pesquisa a um único espaço, você verá imediatamente porque temos de incluir dois espaços:
sed -n '1,4 s / * / / gp' coleridge.txt
Como o asterisco corresponde a zero ou mais do caractere anterior, ele vê cada caractere que não é um espaço como um “espaço zero” e aplica a substituição a ele.
No entanto, se incluirmos dois espaços no padrão de pesquisa, seddeve-se encontrar pelo menos um caractere de espaço antes de aplicar a substituição. Isso garante que os caracteres sem espaço permanecerão intocados.
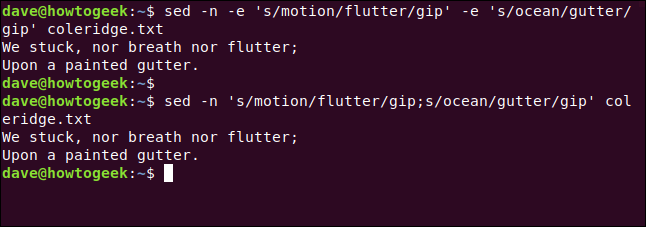
Digitamos o seguinte, usando a -e(expressão) que usamos anteriormente, o que nos permite fazer duas ou mais substituições simultaneamente:
sed -n -e 's / motion / flutter / gip' -e 's / ocean / gutter / gip' coleridge.txt
Podemos obter o mesmo resultado se usarmos um ponto e vírgula ( ;) para separar as duas expressões, assim:
sed -n 's / motion / flutter / gip; s / ocean / gutter / gip' coleridge.txt
Quando trocamos “dia” por “semana” no comando a seguir, a instância de “dia” na expressão “bem por dia” também foi trocada:
sed -n 's / [Dd] ay / semana / gp' coleridge.txt
Para evitar isso, só podemos tentar substituições em linhas que correspondam a outro padrão. Se modificarmos o comando para ter um padrão de pesquisa no início, consideraremos operar apenas em linhas que correspondam a esse padrão.
Nós digitamos o seguinte para tornar nosso padrão de correspondência a palavra “depois”:
sed -n '/ after / s / [Dd] ay / week / gp' coleridge.txt
Isso nos dá a resposta que desejamos.
![Os comandos "sed -n 's / [Dd] ay / semana / gp' coleridge.txt" e "sed -n '/ after / s / [Dd] ay / semana / gp' coleridge.txt" em uma janela de terminal .](https://maisgeek.com/wp-content/uploads/2020/10/20-5.png)
Substituições mais complexas
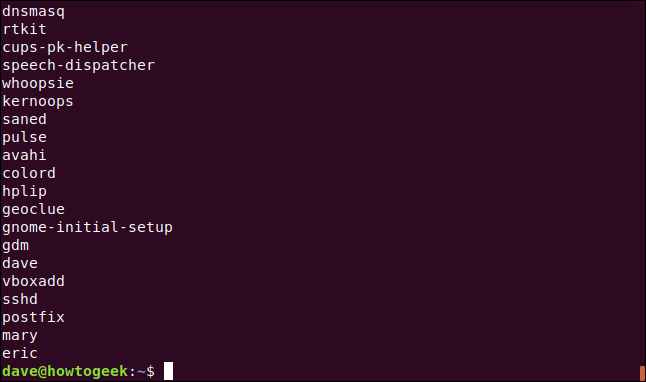
Vamos dar um tempo ao Coleridge e usá-lo sedpara extrair nomes do etc/passwdarquivo.
Existem maneiras mais curtas de fazer isso (mais sobre isso mais tarde), mas usaremos a forma mais longa aqui para demonstrar outro conceito. Cada item correspondido em um padrão de pesquisa (chamado de subexpressões) pode ser numerado (até no máximo nove itens). Você pode então usar esses números em seus sedcomandos para fazer referência a subexpressões específicas.
Você deve colocar a subexpressão entre parênteses [ ()] para que isso funcione. Os parênteses também devem ser precedidos por uma barra invertida ( \) para evitar que sejam tratados como um caractere normal.
Para fazer isso, você digitaria o seguinte:
sed 's / \ ([^:] * \). * / \ 1 /' / etc / passwd
![sed 's / \ ([^:] * \). * / \ 1 /' / etc / passwd em uma janela de terminal](https://maisgeek.com/wp-content/uploads/2020/10/12-1-3.png)
Vamos decompô-lo:
sed 's/: Osedcomando e o início da expressão de substituição.\(: O parêntese de abertura [(] envolvendo a subexpressão, precedido por uma barra invertida (\).[^:]*: A primeira subexpressão do termo de pesquisa contém um grupo entre colchetes. O acento circunflexo (^) significa “não” quando usado em um grupo. Um grupo significa que qualquer caractere que não seja dois pontos (:) será aceito como uma correspondência.\): O parêntese de fechamento [)] com uma barra invertida precedente (\)..*: Esta segunda subexpressão de pesquisa significa “qualquer caractere e qualquer número deles”./\1: A parte de substituição da expressão contém1precedida por uma barra invertida (\). Isso representa o texto que corresponde à primeira subexpressão./': A barra (/) e aspas simples (') encerram osedcomando.
O que tudo isso significa é que vamos procurar qualquer string de caracteres que não contenha dois pontos ( :), que será a primeira instância de texto correspondente. Em seguida, estamos procurando por qualquer outra coisa nessa linha, que será a segunda instância do texto correspondente. Vamos substituir a linha inteira pelo texto que correspondeu à primeira subexpressão.
Cada linha do /etc/passwdarquivo começa com um nome de usuário terminado por dois pontos. Combinamos tudo até o primeiro dois pontos e, em seguida, substituímos esse valor por toda a linha. Portanto, isolamos os nomes de usuário.
A seguir, colocaremos a segunda subexpressão entre parênteses [ ()] para que possamos referenciá-la por número também. Também substituiremos \1 por \2. Nosso comando agora substituirá a linha inteira por tudo, desde os primeiros dois pontos ( :) até o final da linha.
Nós digitamos o seguinte:
sed 's / \ ([^:] * \) \ (. * \) / \ 2 /' / etc / passwd
![O comando "sed 's / \ ([^:] * \) \ (. * \) / \ 2 /' / etc / passwd" em uma janela de terminal.](https://maisgeek.com/wp-content/uploads/2020/10/14-1-5.png)
Essas pequenas alterações invertem o significado do comando e obtemos tudo, exceto os nomes de usuário.
![Saída de sed 's / \ ([^:] * \) \ (. * \) / \ 2 /' / etc / passwd em uma janela de terminal](https://maisgeek.com/wp-content/uploads/2020/10/x15.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.WBDulzIV26.png)
Agora, vamos dar uma olhada na maneira rápida e fácil de fazer isso.
Nosso termo de pesquisa vai do primeiro dois-pontos ( :) ao final da linha. Como nossa expressão de substituição está vazia ( //), não substituiremos o texto correspondente por nada.
Então, digitamos o seguinte, cortando tudo, desde o primeiro dois pontos ( :) até o final da linha, deixando apenas os nomes de usuário:
sed 's /:.*// "/ etc / passwd

Vejamos um exemplo em que referenciamos a primeira e a segunda correspondências no mesmo comando.
Temos um arquivo de vírgulas ( ,) separando nomes e sobrenomes. Queremos listá-los como “sobrenome, nome”. Podemos usar cat, conforme mostrado abaixo, para ver o que há no arquivo:
cat geeks.txt
Como muitos sedcomandos, este próximo pode parecer impenetrável à primeira vista:
sed 's / ^ \ (. * \), \ (. * \) $ / \ 2, \ 1 / g' geeks.txt
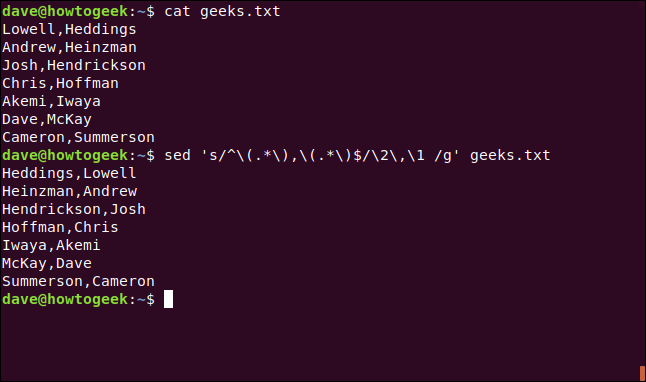
Este é um comando de substituição como os outros que usamos, e o padrão de pesquisa é bastante fácil. Vamos decompô-lo abaixo:
sed 's/: O comando de substituição normal.^: Como o acento circunflexo não está em um grupo ([]), significa “O início da linha”.\(.*\),: A primeira subexpressão é qualquer número de quaisquer caracteres. Está entre parênteses [()], cada um precedido por uma barra invertida (\) para que possamos referenciá-lo por um número. Nosso padrão de pesquisa inteiro até agora se traduz como pesquisa do início da linha até a primeira vírgula (,) para qualquer número de quaisquer caracteres.\(.*\): A próxima subexpressão é (novamente) qualquer número de qualquer caractere. Também está entre parênteses [()], ambos precedidos por uma barra invertida (\) para que possamos fazer referência ao texto correspondente por número.$/: O cifrão ($) representa o final da linha e permitirá que nossa pesquisa continue até o final da linha. Usamos isso simplesmente para apresentar o cifrão. Na verdade, não precisamos disso aqui, pois o asterisco (*) iria para o final da linha neste cenário. A barra (/) completa a seção do padrão de pesquisa.\2,\1 /g': Como colocamos nossas duas subexpressões entre parênteses, podemos nos referir a ambas por seus números. Porque queremos inverter a ordem, nós os digitamos comosecond-match,first-match. Os números devem ser precedidos por uma barra invertida (\)./g: Isso permite que nosso comando funcione globalmente em cada linha.geeks.txt: O arquivo em que estamos trabalhando.
Você também pode usar o comando Cortar ( c) para substituir linhas inteiras que correspondem ao seu padrão de pesquisa. Digitamos o seguinte para pesquisar uma linha com a palavra “pescoço” e substituí-la por uma nova string de texto:
sed '/ neck / c Em volta do meu pulso foi amarrado' coleridge.txt

Nossa nova linha agora aparece na parte inferior de nosso extrato.
Inserindo Linhas e Texto
Também podemos inserir novas linhas e texto em nosso arquivo. Para inserir novas linhas após quaisquer linhas correspondentes, usaremos o comando Append ( a).
Este é o arquivo com o qual trabalharemos:
cat geeks.txt
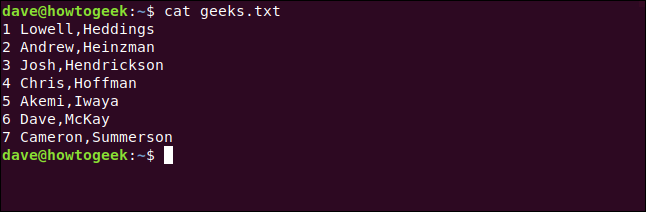
Numeramos as linhas para tornar isso um pouco mais fácil de seguir.
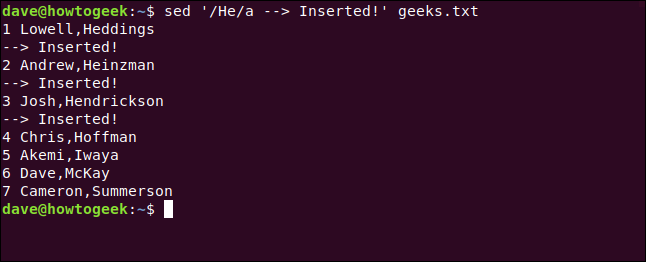
Digamos o seguinte para pesquisar linhas que contenham a palavra “Ele” e inserimos uma nova linha abaixo delas:
sed '/ He / a -> Inserido!' geeks.txt
Digitamos o seguinte e incluímos o comando Insert ( i) para inserir a nova linha acima daquelas que contêm o texto correspondente:
sed '/ He / i -> Inserido!' geeks.txt
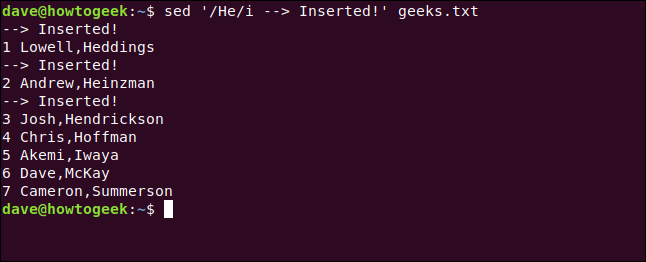
Podemos usar o e comercial ( &), que representa o texto original correspondente, para adicionar um novo texto a uma linha correspondente. \1 , \2e assim por diante, representam subexpressões correspondentes.
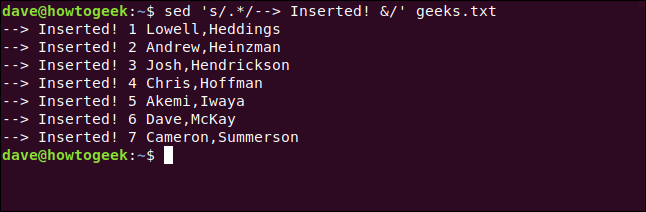
Para adicionar texto ao início de uma linha, usaremos um comando de substituição que corresponde a tudo na linha, combinado com uma cláusula de substituição que combina nosso novo texto com a linha original.
Para fazer tudo isso, digitamos o seguinte:
sed 's /.*/--> Inserido & /' geeks.txt
Digitamos o seguinte, incluindo o Gcomando, que adicionará uma linha em branco entre cada linha:
sed 'G' geeks.txt
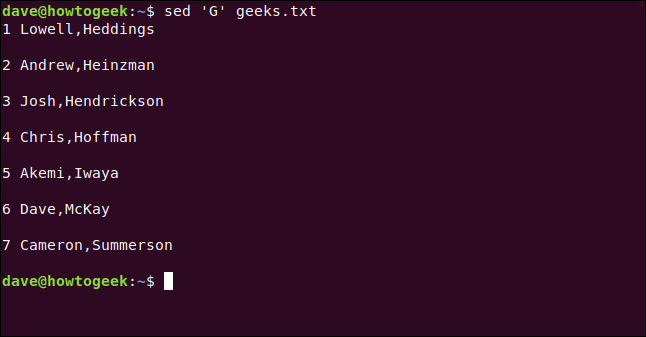
Se você quer adicionar duas ou mais linhas em branco, você pode usar G;G, G;G;Ge assim por diante.
Excluindo linhas
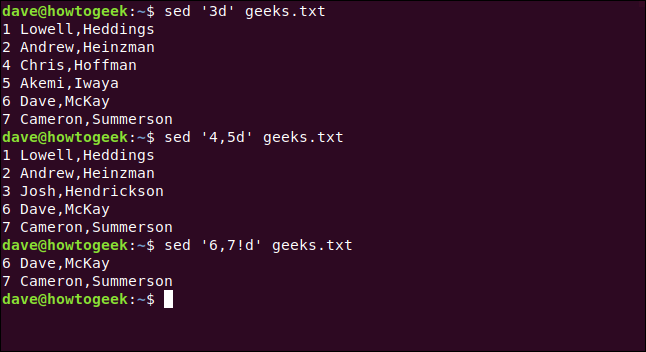
O comando Delete ( d) exclui linhas que correspondem a um padrão de pesquisa ou aquelas especificadas com números de linha ou intervalos.
Por exemplo, para excluir a terceira linha, digitaríamos o seguinte:
sed '3d' geeks.txt
Para excluir o intervalo de linhas quatro a cinco, digitaríamos o seguinte:
sed '4,5d' geeks.txt
Para excluir linhas fora de um intervalo, usamos um ponto de exclamação ( !), conforme mostrado abaixo:
sed '6,7! d' geeks.txt
Salvando suas alterações
Até agora, todos os nossos resultados foram impressos na janela do terminal, mas ainda não os salvamos em nenhum lugar. Para torná-los permanentes, você pode gravar suas alterações no arquivo original ou redirecioná-las para um novo.
Substituir o arquivo original requer algum cuidado. Se o seu sedcomando estiver errado, você pode fazer algumas alterações no arquivo original que são difíceis de desfazer.
Para sua tranquilidade, sed pode criar um backup do arquivo original antes de executar seu comando.
Você pode usar a opção No local ( -i) para informar sedpara gravar as alterações no arquivo original, mas se você adicionar uma extensão de arquivo a ele, sed o backup do arquivo original será feito em um novo. Ele terá o mesmo nome do arquivo original, mas com uma nova extensão de arquivo.
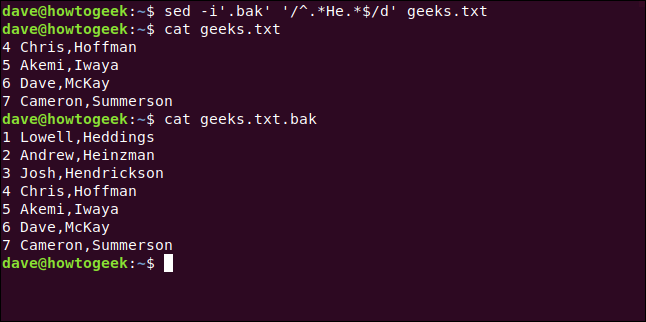
Para demonstrar, vamos procurar todas as linhas que contenham a palavra “He” e apagá-las. Também faremos backup de nosso arquivo original em um novo usando a extensão BAK.
Para fazer tudo isso, digitamos o seguinte:
sed -i'.bak '' /^.*He.*$/d 'geeks.txt
Digitamos o seguinte para garantir que nosso arquivo de backup não seja alterado:
cat geeks.txt.bak
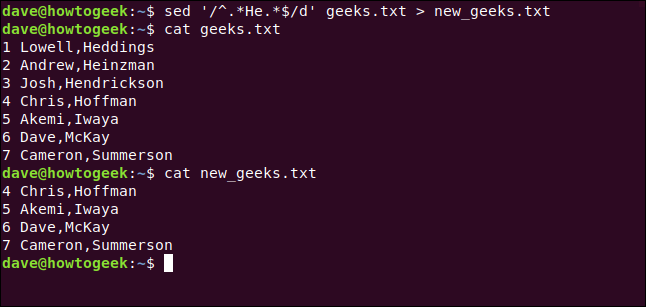
Também podemos digitar o seguinte para redirecionar a saída para um novo arquivo e obter um resultado semelhante:
sed -i'.bak '' /^.*He.*$/d 'geeks.txt> new_geeks.txt
Usamos catpara confirmar se as alterações foram gravadas no novo arquivo, conforme mostrado abaixo:
cat new_geeks.txt
Tendo sed tudo isso
Como você provavelmente notou, mesmo esta introdução rápida sedé bastante longa. Este comando tem muito a ver e ainda mais coisas que você pode fazer com ele .
Felizmente, porém, esses conceitos básicos forneceram uma base sólida sobre a qual você pode construir à medida que aprende mais.


